자료구조 .. 언제 배웠더라? 17년도에 배웠다.
최근에 코테를 풀면서 자료구조가 많이 헷갈리기도 하고 .. Python으로 자료구조를 지대루 짠 적이 없어서 공부한다 !
하지만 나의 기억력은 쓰레기 .. ㅋㅋ 기술면접 때도 봐야 하므로 여기에 정리하면서 공부해야겠다.
Hash Table (해쉬 테이블)
1. 해쉬 구조란?
- Key - Value 쌍으로 이루어진 데이터 구조를 의미한다. Key를 이용하여 데이터를 찾으므로 속도가 빠른 구조다.
- 파이썬에서는 Dictionary 타입이 해쉬 테이블과 같은 구조다.
- 검색을 많이 할 때 / 캐쉬를 구현할 때 / 저장, 삭제, 읽기가 많은 경우에 주로 사용한다.
2. 해쉬 구조의 장점과 단점
장점)
- 데이터 저장 및 검색 속도가 빠르다.
- 해쉬는 키에 대한 중복 확인이 쉽다.
단점)
- 저장공간이 많이 필요하다.
- 여러 키에 대한 주소가 동일한 경우 충돌을 해결하기 위한 충돌 해결 알고리즘이 필요하다.
3. 시간 복잡도
- 충돌이 없는 경우 : O(1)
- 모든 경우에 충돌이 발생하는 경우 : O(n)
(HashTable은 일반적으로 충돌이 없는 경우를 기대하고 만들기 때문에 O(1)이라고 말할 수 있음)

SHA ( Secure Hash Algorithm )
해쉬 함수(Hash Function)은 임의의 길이의 데이터를 고정된 길이로 매핑해주는 함수다.
hashlib는 SHA 함수들을 가지고 있는 라이브러리다.
1. SHA-1
- SHA-1은 해쉬값의 크기를 160으로 고정하는 알고리즘이다.
import hashlib data = 'hash_study'.encode() hash_object = hashlib.sha1() hash_object.update(data) hex_dig = hash_object.hexdigest() print(hex_dig) data2 = 'nara_blog'.encode() hash_object2 = hashlib.sha1() hash_object2.update(data2) hex_dig2 = hash_object2.hexdigest() print(hex_dig2)

2. SHA-256
- SHA-256은 해쉬값의 크기를 256으로 고정하는 알고리즘이다. SHA-1 보다 해쉬값의 크기가 커져서 더 안전한 알고리즘이다.
(위의 코드 sha1()을 sha256()으로 바꿔서 사용이 가능하다.)
SHA-256 출력값
리스트로 Hash table 구현하기
class HashTable:
def __init__(self):
self.hash_table = list([0 for i in range(8)])
def hash_func(self, key):
return key%8
def insert(self, key, value):
hash_value = self.hash_func(hash(key))
self.hash_table[hash_value] = value
def read(self, key):
hash_value = self.hash_func(hash(key))
return self.hash_table[hash_value]
def print(self):
print(self.hash_table)
ht = HashTable()
ht.insert(1, 'one')
ht.print()
ht.insert(2, 'two')
ht.print()
ht.insert('nara', 'choi')
ht.print()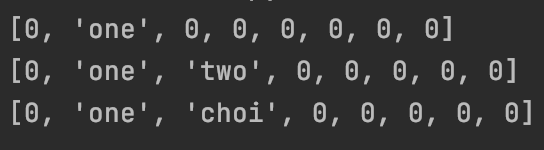
0으로만 이루어진 리스트를 생성하는데 이 해쉬 테이블의 공간은 8자리이다. 해쉬 키를 생성할 때는 파이썬의 내장 함수 hash()를 사용했다. hash() 함수는 랜덤 연산 작용이기 때문에 실행시 값이 항상 다르다.
해쉬 함수는 key % 8로 설정했다. insert 함수를 통해 key, value 쌍을 해쉬 테이블에 넣을 수 있고 read 함수를 통해 key 값을 이용하여 value 값을 얻을 수 있다. print 함수를 통해 해쉬 테이블을 출력할 수 있다.
여기서 hash table의 문제가 발생한다. (2, 'two') 쌍을 삭제하지 않았음에도 불구하고 insert('nara', 'choi')를 실행하자 hash의 계산값이 겹쳐서 충돌이 발생한다. 이런 충돌을 해결하는 것이 해쉬 함수의 핵심이다.
충돌 해결 알고리즘
위의 문제를 해결하기 위한 3가지 충돌 알고리즘 (Chaining 기법, Linear Probing 기법, 공간 확장 기법) 이 있다.
1. Chaining 기법
- Open Hashing 기법 중 하나로서, 해쉬테이블 저장공간 외에 공간을 더 추가해서 사용하는 방법
- 충돌이 발생시 linked list로 데이터를 추가로 뒤에 연결시키는 방법
class hashTable:
def __init__(self):
self.hash_table = list([0 for i in range(8)])
def hash_func(self, key):
return key % 8
def insert(self, key, value):
gen_key = hash(key) #내장함수 hash로 해쉬 키 생성
hash_value = self.hash_func(gen_key) #hash_func를 통해 해쉬 키에 맞는 해쉬 값 생성
if self.hash_table[hash_value] != 0: #hash value index를 사용하고 있어서 충돌이 발생하는 경우
for i in range(len(self.hash_table[hash_value])):
if self.hash_table[hash_value][i][0] == gen_key: #이미 같은 키 값이 존재하면 value를 교체한다.
self.hash_table[hash_value][i][1] = value
return
self.hash_table[hash_value].append([gen_key, value]) #같은 키 값이 존재하지 않는다면 [key, value] 쌍을 해당 index에 insert
else:
self.hash_table[hash_value] = [[gen_key, value]] # hash_value index를 사용하고 있지 않아서 충돌이 발생하지 않을 때
def read(self, key):
gen_key = hash(key)
hash_value = self.hash_func(gen_key)
if self.hash_table[hash_value] != 0:
for i in range(len(self.hash_table[hash_value])):
if self.hash_table[hash_value][i][0] == gen_key:
return self.hash_table[hash_value][i][1]
return None
else:
return None
def print(self):
print(self.hash_table)
ht2 = hashTable()
ht2.insert(1, 'one')
ht2.print()
ht2.insert(2, 'two')
ht2.print()
ht2.insert('nara', 'choi')
ht2.print()
위의 방식과는 다르게 충돌이 발생하면 해당 인덱스의 리스트에 [key, value] 쌍을 추가한다. 이 방법은 key, value 쌍을 계속 추가할 수 있다는 장점이 있지만 공간 효율성이 떨어진다는 단점이 있다. (하나의 index에 값이 계속 추가된다면 불균형한 구조가 되기 때문이다.)
2. Linear Probing 기법
- Close Hashing 기법 중에 하나로서, 해쉬 테이블 저장공간 안에서 충돌문제를 해결하는 방법이다.
- 충돌이 발생하면 해당 hash address의 다음 Index부터 맨 처음 나오는 빈공간에 저장하는 기법이다.
(Chaning 기법과 비교했을 때, 공간 활용도가 증가한다.)
class HashTable:
def __init__(self):
self.hash_table = list([0 for i in range(8)])
def hash_func(self, key):
return key%8
def insert(self, key, value):
gen_key = hash(key)
hash_value = self.hash_func(gen_key)
if self.hash_table[hash_value] != 0: #hash value index를 사용하고 있어서 충돌이 발생하는 경우
for i in range(hash_value, len(self.hash_table)): # 해당 Index부터 마지막 index까지 for문을 돈다.
if self.hash_table[i] == 0: #해당 index가 비어있으면 [key, value]를 insert
self.hash_table[i] = [gen_key, hash_value]
return
elif self.hash_table[i][0] == gen_key: #해당 index에 이미 같은 키 값이 존재하면 덮어쓴다.
self.hash_table[i][1] = value
return
else:
self.hash_table[hash_value] = [gen_key, value]
def read(self, key):
gen_key = hash(key)
hash_value = self.hash_func(gen_key)
if self.hash_table[hash_value] != 0:
for i in range(hash_value, len(self.hash_table)):
if self.hash_table[i] == 0:
return None
elif self.hash_table[i][0] == gen_key:
return self.hash_table[i][1]
else:
return None
def print(self):
print(self.hash_table)
ht3 = HashTable()
ht3.insert(1, 'one')
ht3.print()
ht3.insert(2, 'two')
ht3.print()
ht3.insert('nara', 'choi')
ht3.print()
충돌이 발생했을 때, 다음 Index부터 값을 채운다. 하지만 미리 지정한 자릿수가 넘어가면 충돌이 발생한다는 단점이 있다.
3. 공간을 확장하는 방법
class HashTable:
def __init__(self, n):
self.n = n
self.hash_table = list([0 for i in range(8)])
def hash_func(self, key):
return key % self.n저장 공간을 확대하여 HashTable을 생성하면 2에서 발생하는 충돌을 조금은 방지할 수 있다.
'자료구조' 카테고리의 다른 글
| [Python] - Tree (0) | 2021.07.22 |
|---|